

Contents

Deployment Environments
There are different environments where you can deploy an application, they could be summarized in public cloud, private cloud, hybrid cloud and edge computing. I think that cloud deployments are widely defined everywhere so I’m not really going to spend time on those.
Is worth mentioning that private cloud differs from a private data center, since the former implies that there is a layer of abstraction and orchestration to manage the environment, resembling the public cloud but within the organization control.
The hybrid cloud deployment as the name implies is a mix of environments depending on the need and regulatory restrictions, which in my opinion is the best option to achieve efficiency, using the best of both worlds, but of course, everything is a tradeoff and in this case we would add the complexity of managing both environments.
There is another environment that is not widely used yet but it is useful for latency sensible applications, like some IOT uses (autonomous vehicles, medical surgery, etc.) and that is edge compute, this is a distributed computing paradigm instead of centralizing everything in a data center, this brings computation and data storage closer to the location where it is needed, to improve response times and save bandwidth. There is a lot of debates regarding the downsides of this design, but I’m sure that this will be really useful for some cases.
Once we determined where we are going to deploy the application, now we need to evaluate how is going to be deployed, the main options could be, in a bare metal, virtual machines or containers.
- Bare Metal is the use of a physical appliance where you dedicate all the resources for an application, they are useful when you need a lot of resources, or for legacy applications that cannot be virtualized. Nowadays I think that virtualization is mature enough to provide the needed resources as well.
- Virtualization uses software to create an abstraction layer over the hardware that allows the resources to be divided into multiple virtual machines (VMs). Each VM runs its own operating system (OS) and behaves like an independent computer, even though it is running on just a portion of the actual underlying computer hardware. There are two main types of hypervisors, "Type 1" or "bare metal" and "Type 2" or "hosted".
Type 1 (e.g. VMWare ESXi), acts like a lightweight operating system and runs directly on the host's hardware, while a type 2 hypervisor (e.g. VirtualBox) runs as a software layer on an operating system, like other computer programs.
Sometimes the categorization of the hypervisors doesn't exactly falls into one of these two types, like KVM, an open source virtualization technology that changes the Linux kernel into a hypervisor that can be used for virtualization, which is considered a type 1 hypervisor, but is not entirely true.
In summary, virtualization allows us to make an efficient use of the host resources, having multiple environments in the same hardware, and because of this, there is the need to monitor the usage of these resources to make sure everything gets their needed quota. - Containers are the main focus nowadays because of the "improvements" from previous virtualization technologies, mainly for their portability, small size and often faster to deploy. This blog as you can see in my first post, uses Docker to package the base image which includes Jekyll application.
It achieves this by only needing one OS and a container runtime which would manage all the interactions between the containers themselves and also the kernel, differentiating from virtual machines where you need the hypervisors plus each VM full OS, being the last one a huge overhead.
Taking this into account, we could say that from the operational perspective, we might needed less resources to maintain containers than for VMs, since you would only need to maintain and secure one OS, one Kernel, etc.
Containers technology implementations, like with hypervisors, may slightly vary depending on the software used, in this case I will use LXC/LXD and Docker as examples.
- LXC (Linux Containers) is an open source OS-level Virtualization, that could be seen as a middle ground between hypervisors and containers, since it allows the user to spin up virtual machines or "machine containers" without an hypervisor, this is achieved providing a common Linux kernel in the host which all the machine containers share, making the guest OS lighter than a normal VM, but this also implies that only supports certain OS based on this kernel (not Windows) and there would be a strong correlation between the containers and the host's Linux kernel.
Isolation between containers is done via cgroups and namespaces in the kernel, but it is not a secure virtualization technology for multi-tenant environments. Regarding the networking it seems to be more limited or harder to manage than Docker.
LXD (Linux Containers Daemon) is the control plane for LXC. It is a system container manager that works as a privileged daemon which exposes a REST API to extend the LXC containers features and integration capabilities. - Docker, on the other hand is a container runtime that would run on top of a host OS and focused on running single applications instead of full or partial OS like LXC/LXD. This allows applications to run independently of an operating system as long as they have this container engine running, so they are extremely portable.
- LXC (Linux Containers) is an open source OS-level Virtualization, that could be seen as a middle ground between hypervisors and containers, since it allows the user to spin up virtual machines or "machine containers" without an hypervisor, this is achieved providing a common Linux kernel in the host which all the machine containers share, making the guest OS lighter than a normal VM, but this also implies that only supports certain OS based on this kernel (not Windows) and there would be a strong correlation between the containers and the host's Linux kernel.
Like always there are many things to consider with these technologies and their variants, everything has benefits and drawbacks, so you should need take those into account together with the application or business needs before using one or the other.
In the following image you could find a visualization of some of the different hypervisor and container technologies previously discussed.
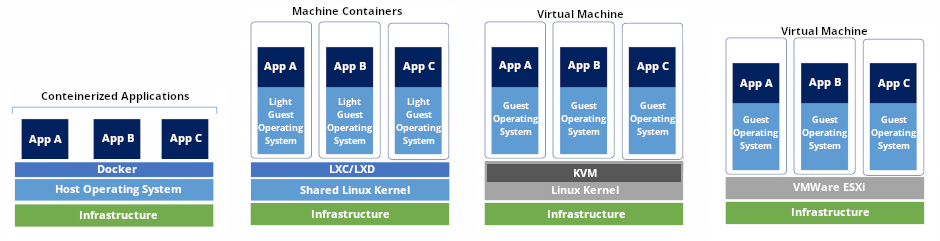

Docker
Docker engine is a container runtime that runs on various Linux and Windows operating systems. Docker creates simple tooling and a universal packaging approach that bundles up all application dependencies inside a container which is then run on Docker Engine. This enables applications to run anywhere consistently on any infrastructure, solving dependency problems and eliminating the “it works on my laptop!” problem.
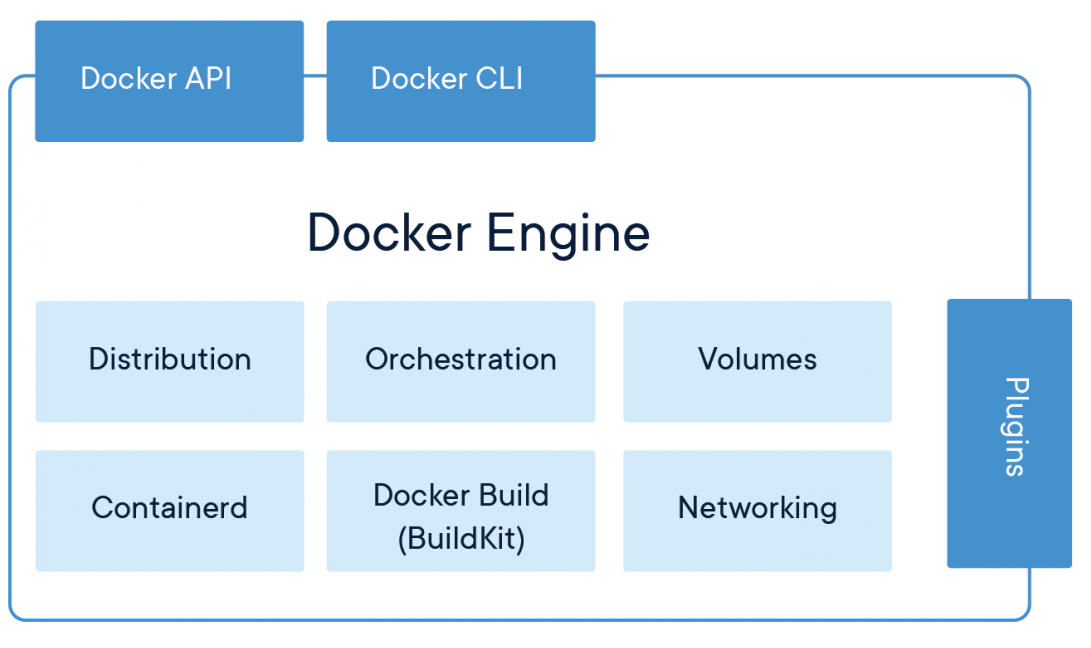
Container images are lightweight, standalone, executable packages of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. Images become containers at runtime in the case of Docker with the use of Docker Engine.
DockerFile is a text document that contains all the commands a user could call on the command line to assemble an image. Using Docker build users can create an automated build that executes several command-line instructions in succession from a Dockerfile.
You can find more details in Docker docs’ page, which describes the commands you can use in a Dockerfile, and Dockerfile Best Practices for a tip-oriented guide.
Container Orchestration Tools
Docker Compose is a tool for defining and running multi-container Docker applications on the same host. Compose uses a YAML file to configure the application’s services, and with a single command, you create and start all the services from your configuration. Compose relies on Docker Engine so the runtime must be also installed.
Docker Swarm is a cluster management and orchestration feature embedded in the Docker Engine using swarmkit, a separate project which implements Docker’s orchestration layer and is used directly within Docker.
A swarm consists of multiple hosts which run in swarm mode and act as managers (to manage membership and delegation) and workers (which run swarm services). A host can be a manager, a worker, or perform both roles.
Docker works to maintain that desired state. For instance, if a worker node becomes unavailable, Docker schedules that node’s tasks on other nodes. (A task is a running container which is part of a swarm service and managed by a swarm manager, as opposed to a standalone container)
Kubernetes is pretty similar to Docker Swarm, there is some debate regarding which one is better for certain deployments, but as a general rule of thumb, Kubernetes is broader than Docker Swarm, it provides better scalability and would support higher demands with more complexity while Docker Swarm is easier to deploy for a quick start with orchestration tools.
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, which facilitates both declarative configuration and automation, it combines over 15 years of Google’s experience running production workloads at scale.

Twelve-Factor App
The twelve-factor app is a methodology for building software-as-a-service apps that was drafted by developers at Heroku, a platform-as-a-service company.
I highly recommend looking at Adam Wiggins’s webpage which has detailed information of each of these factors, as a quick summary, these factors are:
- Codebase, One codebase tracked in revision control, many deploys
- Dependencies, Explicitly declare and isolate dependencies
- Config, Store config in the environment
- Backing services, Treat backing services as attached resources
- Build, release, run, Strictly separate build and run stages
- Processes, Execute the app as one or more stateless processes
- Port binding, Export services via port binding
- Concurrency, Scale out via the process model
- Disposability, Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity, Keep development, staging, and production as similar as possible
- Logs, Treat logs as event streams
- Admin processes, Run admin/management tasks as one-off processes

DevOps Practices
Due to the need of organizations to innovate faster and transform how they build and deliver software, the DevOps model arose, bringing some practices to fulfill those needs.
One fundamental practice is to perform very frequent but small updates, these updates make each deployment less risky and easier to address bugs.
Another practice is to use a micro services architecture to make their applications more flexible and enable quicker innovation. The micro services architecture decouples large, complex systems into simple, independent projects.
These DevOps practices are merging into the networking realm by addressing some of the same needs but in a different context, in the infrastructure world we are moving towards a more automated, less error prone and more agile way of working and taking the software development experience as our knowledge base, we can extrapolate them to our area.
DevOps best practice could be summarize as follows:
- Continuous Integration is the regular merge of code changes into a central repository, after which automated builds and tests are run to find and address bugs quicker, improve quality, and reduce validation time.
- Continuous Delivery expands upon continuous integration by deploying all code changes to a testing environment and/or a production environment after the build stage. When continuous delivery is implemented properly, all deployments would have passed through a standardized test process beforehand.
- Micro Services as we stated before, is the decoupling of large and complex systems into simple, independent projects. Each service runs in its own process and communicates with other services through a well-defined interface or API.
- Infrastructure as Code is a practice where the infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration. The APIs enables developers and administrators to interact with infrastructure programmatically, and at scale. Because they are defined by code, infrastructure and servers can quickly be deployed using standardized patterns, updated with the latest patches and versions, or duplicated in repeatable ways.
- Monitoring and Logging
- Communication and Collaboration is one of the key cultural aspects of DevOps. The use of DevOps tooling and automation of the delivery process brings together the workflows and responsibilities of development and operations, bounding the success of the whole model on the collaboration of the teams involved.
CI/CD Pipeline
Taking as a reference Amazon’s documentation, we can breakout the CI/CD Pipeline in different phases:
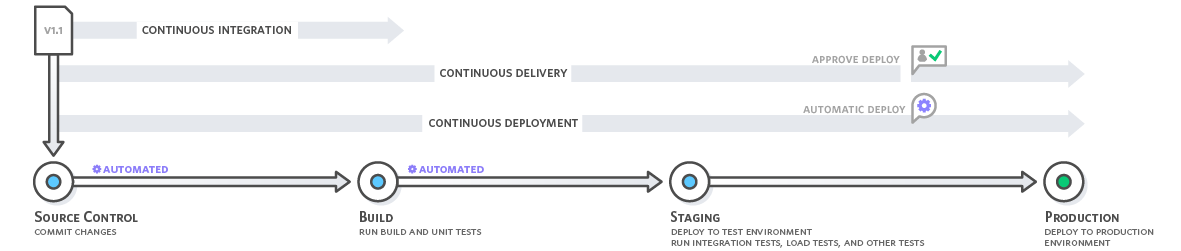
Continuous integration refers to the build and unit testing stages of the software release process and the difference between continuous delivery and continuous deployment is the presence of a manual approval to update to production.
Some CI/CD best practices are:
- Test Driven Development (TDD) is the practice of writing out the test code and test cases before doing any actual feature coding. This is an extensive topic on its own, but we could summarize the sequence based on Kent Beck's "Test Driven Development: By Example" book:
- Add a test - Write a test that defines a function or improvements of a function.
- Run all tests and see if the new test fails - This validates that the test is working correctly.
- Write the code - The next step is to write the code that causes the test to pass and the code must not go beyond the functionality that the test checks.
- Run tests - If all test cases now pass, the new code meets the test requirements.
- Refactor code - The growing code base must be cleaned up regularly during test-driven development and by continually re-running the test cases throughout each refactoring phase, the developer can be confident that process is not altering any existing functionality.
- Repeat - Starting with another new test, the cycle is then repeated to push forward the functionality.
- Pull requests and code review is a pipeline best practice used also in open source projects workflows as I explained in my previous post. A pull request is created when a developer is ready to merge new code into the main codebase. The pull request notifies other developers of the new set of changes that are ready for integration.
This pull request is a good kick off for the CI pipeline and run the set of automated approval steps. An additional, manual approval step is commonly added at pull request time, during which a non-stakeholder engineer performs a code review of the feature.(Four eye review principle or peer review) - Optimize pipeline speed
- Single method of deployment it's critical to avoid manual changes and the problems this implies. Once a continuous deployment pipeline is in place, it must be the only method of deployment.
- Containerization should be leveraged, to ensure the same behavior across multiple hosts.
Pipeline Tools
Personally, I find really useful as a starting point, to have some examples of common tools, since you could extrapolate from there and it would be easier to find different options and more information, which is what I would like to do here.
- pylint - Linting is the process of analyzing code and flag some suspicious constructs (likely to be bugs) in source code, generally this tools perform static program analysis (performed without actually executing programs) which is especially useful for interpreted languages like JavaScript and Python, because such languages lack a compiling phase
- pytest - Unit test, test a unit of the program, it helps developers to know whether the individual unit of the code is working properly or not.
Pytest makes it easy to write small tests in a .py file and scales to support complex functional testing for applications and libraries. - Selenium - System testing is done by both testers and developers, to check whether the software or product meets the specified requirements or not. After system testing, there is usually an acceptance test performed by testers, stakeholders as well as clients and is used to check whether the software meets the customer requirements or not
I found really useful Guru99's post explaining Selenium in more depth. Selenium is a free, open-source software suite for automating web applications, across different browsers and platforms, for testing purposes but is certainly not limited to just that. A somewhat similar and commercial option to Selenium would be now Micro Focus's UFT.
As a quick overview, Selenium's suite is composed by:- WebDriver uses browser automation APIs provided by browser vendors to control browser and run tests. This is as if a real user is operating the browser. Since WebDriver does not require its API to be compiled with application code.
- IDE is the tool used to develop test cases. It's an easy-to-use Chrome and Firefox extension and is generally the most efficient way to develop test cases. It records the user’s actions in the browser, using existing Selenium commands, with parameters defined by the context of that element. Great way to learn Selenium script syntax and save time.
- Grid allows you to run test cases in different machines across different platforms. The control of triggering the test cases is on the local end, and they are automatically executed by the remote end. In summary, helps you running tests on multiple browser and operating system combinations.
- Travis CI and Jenkins - Building the pipeline, to help automate software development (building, testing, and deploying) there are several tools that facilitate continuous integration and continuous delivery/deployment, but our focus would be only in Travis CI and Jenkins.
- Travis CI is a commercial hosted continuous integration service, which integrates with the common cloud repositories like GitHub and Bitbucket, meaning that you can monitor your projects and trigger the pipeline after a change.
The commands to test the code are taken from a file named .travis.yml which sits along your project code. This makes it easy to have different test code per branch since each branch can have its own file.
Travis CI is free for open source projects and they also have an enterprise on-premises product. It might be easier tool to start with. - Jenkins is like Travis CI, a tool for automating software development but free and open source. It also requires to run and maintain a dedicated server, is highly configurable which gives flexibility but also added complexity, some of it might be eased by the use of many plugins that allow developers to alter how Jenkin looks and operates.
For example, Jenkins Job DSL allows jobs to be defined in a programmatic form in a human readable file, no need to use the UI.
Even though Jervis is not a plugin, is a Travis-like Jenkins job generation library for Job DSL plugin groovy scripts. Reads a .jervis.yml file and generates a job in Jenkins, and if one doesn't exist, it falls back to using the .travis.yml
- Travis CI is a commercial hosted continuous integration service, which integrates with the common cloud repositories like GitHub and Bitbucket, meaning that you can monitor your projects and trigger the pipeline after a change.

OWASP
The Open Web Application Security Project (OWASP) is a nonprofit foundation that works to improve the security of software. It produces freely-available articles, methodologies, documentation, tools, and technologies in the field of web application security.
One of their most interesting publication is the OWASP Top Ten Web Application Security Risks which represents a broad consensus about the most critical security risks to web applications.
I don’t see the point on going through each of them since they explain them pretty well in their webpage, the most relevant for the exam are XSS, SQL injections, and CSRF.

Databases Types
This part of the post is a little bit off topic but coming from a networking background, I found it really useful to expand my understanding of the different components which I have never been involve with. I’m glad that Nick Russo touched on this in his Pluralsight courses, so I’m going to keep this for my future reference and maybe help you in the same way.
A database is an organized collection of information, or data, typically stored electronically in a computer system. A database is usually controlled by a database management system (DBMS). Together, the data and the DBMS, along with the applications that are associated with them, are referred to as a database system, often shortened to just database.
There are basically two types of databases, relational, the oldest general purpose database and the rest, non-relational databases which are optimized for the specific requirements of the type of data being stored.
Relational DB
Relational databases are a collection of data items with pre-defined relationships between them. It organizes data using tables, each column within a table has a name and a data type and each row represents an individual record or data item within the table (tuple), which contains values for each of the columns. The querying language called SQL (Structured Query Language), was created to access and manipulate data stored with that format.
Special fields in tables, called foreign keys, can contain references to columns in other tables. This allows the database to bridge the two tables on demand to bring different types of data together.
Relational databases are good for any data that is regular and predictable, on the other hand it can be challenging to alter the structure of data after it is in the system.
Relational database transactions have a set of properties called ACID:
- Atomic, requires that either transaction as a whole be successfully executed or if a part of the transaction fails, then the entire transaction be invalidated.
- Consistent, ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct.
- Isolated, is critical to achieving concurrency control and makes sure each transaction is independent unto itself.
- Durable, requires that all of the changes made to the database be permanent once a transaction is successfully completed.
Examples of relational databases can be MySQL, MariaDB, PostgreSQL, and SQLite.
Non-Relational DB
Non-relational databases are databases that does not use the tabular schema of rows and columns found in most traditional database systems. Like I stated before, they use a storage model that is optimized for the specific requirements of the type of data being stored, they tend to be more specific in the type of data they support and how data can be queried. For example, time series data stores are optimized for queries over time-based sequences of data.
The term NoSQL refers to data stores that do not use SQL for queries, and instead use other programming languages and constructs to query the data. In practice, “NoSQL” means “non-relational database,” even though many of these databases do support SQL-compatible queries. However, the underlying query execution strategy is usually very different from the way a traditional RDBMS (Relational Database Management System).
The CAP Theorem, states that a distributed data store “cannot” simultaneously offer more than “two of three” established guarantees:
- Consistency, already defined.
- Availability.
- Partition Tolerance: Even if communication among the servers is no longer reliable, the system will continue to function.
So taking into account the CAP theorem, Eric Brewer defined the BASE consistency model which relaxes the consistency property of transactions.
- Basically available indicates that the system does guarantee availability, supporting partial failures without total system failure.
- Soft state indicates that the state of the system may change over time, even without input, relying on the eventual consistency model.
- Eventual consistency indicates that the system will become consistent over time, assuming that the system doesn't receive input during that time.
There is a wide-range of categories of NoSQL databases, I will not go deeper on each this time, but the ones that might be more relevant for us are:
- Columnar databases organizes data into columns and rows. While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in data aggregation and analytical applications.
Unlike a key/value store or a document database, most column-family databases physically store data in key order, rather than by computing a hash. The row key is considered the primary index and enables key-based access via a specific key or a range of keys. Some implementations allow you to create secondary indexes over specific columns in a column family. Secondary indexes let you retrieve data by columns value, rather than row key.
Popular implementations: Cassandra, HBase in HDInsight (Azure), Redshift (AWS) and BigQuery (GCP). - Key/value database is essentially a large hash table, storing arbitrary data accessible through a specific key. To store data, you provide a key and the blob of data you wish to save, on the other hand, to retrieve data, you provide the key and will then be given the blob of data back. The data values are an opaque collection, which may have different fields for every record.
Use cases could be session-related data store or shopping carts.
Popular implementations: MemcacheDB, Redis, Azure Cache for Redis, DynamoDB (AWS) and Cloud Memorystore (GCP). - Graph databases are purpose-built to store and navigate relationships. This DB manages two types of information, nodes and edges, nodes represent entities, and edges specify the relationships between these entities. An edge always has a start node, end node, type, and direction, and there is no limit to the number and kind of relationships a node can have.
Graph databases have advantages for use cases such as social networking, recommendation engines, and fraud detection, when you need to create relationships between data and quickly query these relationships.
Popular implementations: Neo4j, Cosmos DB Graph API (Azure) and Neptune (AWS). - Time Series databases are a set of values organized by time, this database is optimized for this type of data, like telemetry data from IoT sensors. It must support a very high number of writes, as they typically collect large amounts of data in real time from a large number of sources. Updates are rare, and deletes are often done as bulk operations.
This type of database also handle out-of-order and late-arriving data, automatic indexing of data points, and optimizations for queries described in terms of windows of time, in order to support time series visualizations, which is a common way that time series data is consumed.
Popular implementations: InfluxDB, Prometheus, Time Series Insights (Azure), Timestream (AWS) and Cloud Bigtable (GCP) - Object databases are optimized for storing and retrieving large binary objects or blobs, an object consists of the stored data, some metadata, and a unique ID for accessing the object. Object stores are designed to support files that are individually very large, as well provide large amounts of total storage to manage all files.
There are several use cases for this type of data store, but some of them are data lakes and big data analytics, archiving, Disaster recovery (DR) and Cloud-native applications.
Popular implementations: Db4o, Blob Storage (Azure), S3 (AWS) and Cloud Storage (GCP) - Document databases are a type of non-relational database that is designed to store and query data typically as JSON-like documents, but also accepts formats like XML, YAML, BSON, or even plain text, this makes it easier for developers to store and query data by using the same format they use in their application code.
They work well for catalogs, user profiles and content management systems, where each document is unique and evolves over time.
Popular implementations: MongoDB, Cosmos DB (Azure), DocumentDB (AWS) and Cloud Firestore (GCP).
ORM & ONDM
Object Relational Mapping (ORMs) is a programming technique for converting data between incompatible type systems using object-oriented programming languages. This allows us to manipulate and query relational databases without the use of SQL, instead we can use the programing language of our preference using a specific library. For example, for python there is SQLAlchemy.
Object-NoSQL Database Mappers (ONDMs), just like ORMs, ONDMs provide a uniform abstraction interface for different NoSQL technologies, I found these harder to find for python, but I’m sure there are a wide selection of tools, some of them for example are neo4django, bulbflow
Some of the downsides of using an ORM are:
- Impedance mismatch (Inherent difficulties in the translation when moving data between relational tables and application objects).
- Complexity from database into the application code.
- Potential for reduced performance.