Infrastructure as code is an approach to infrastructure automation based on practices from software development, which provides the ability to create, configure, and manage complex infrastructures by means of executable code, reducing costs, improving speed and reducing the risks.
The need to connect to multiple devices to achieve a desired state would be replaced by this new approach.
Since the infrastructure would be managed as code, this allows developers to make use of the different tools and principles from software development, like version control systems, test-driven development, continuous integration and continuous delivery or deployment.
Infrastructure as Code Principles
Easily Reproduced
Disposable
Consistent
Repeatable
Change is assured
Idempotence - is an element of a set which is unchanged in value when multiplied or otherwise operated on by itself. In other words, an operation only occur if the current value or state is different, if it is the same, no action should be taken.
This new type of infrastructure management is called “controller-level management”, while the older way of managing networks, connecting directly into devices via CLI is called “device-level management”
Model-Driven Telemetry
Network operators have heavily relied in SNMP, CLI and Syslog to gather data regarding network state, hot spots in the network, or for decision making, but these have limitations that restrict automation and scale.
The traditional use of the pull model, where the client requests data from the network does not scale when what you want is near real-time data.
Model-Driven Telemetry (MDT) is a new approach for network monitoring in which data is streamed from network devices continuously using a push model and provides near real-time access to operational statistics.
Applications can subscribe to specific data items they need, by using standards-based YANG data models over NETCONF, RESTCONF, or gRPC Network Management Interface (gNMI) protocols
Push vs Pull/Polling
Collecting data for analyzing and troubleshooting has always been an important aspect in monitoring the health of a network.
Pull or polling based solutions are quite common in monitoring (SNMP, CLI, Syslog), providing a centralized structure which queries a monitored component. The main drawback for this approach is the scalability when there is more than one network management station (NMS) in the network.
Push monitoring as you must expect, works the other way around, the component being monitored becomes the initiator, pushing metrics and events on some time interval. Whit this approach the monitoring system do not need to pre-register the monitored component.
This second approach works like the Observer Design Pattern previously explained, avoiding also remote connections which in turn reduces the complexity of the security model for the network.
The push model is the one preferred for MDT.
Dial-in vs Dial-Out
Before going through each case, is worth noting that both models updates are pushed from the device to the receiver or NMS, no polling is done.
For Dial-in mode, an MDT receiver dials in to the router, and subscribes dynamically to one or more sensor paths or subscriptions, the subscription ID is dynamically generated and this subscription terminates when the receiver cancels such subscription. In Dial-in mode the router acts as the server and the receiver is the client.
Dial-in subscriptions need to be reinitiated after a reload, because established connections or sessions are killed during stateful switchover. Also, whenever the session breaks, is the receiver the one that re-establishes the session.
On the other hand, in Dial-out mode the router dials out to the receiver, the router acts as a client and the receiver acts as a server.
Dial-out subscriptions are created as part of the device configuration, the sensor-paths and destinations are configured and bound together into one or more subscriptions, with fixed subscriptions ID. The router continually attempts to establish a session with each destination in the subscription, and streams data to the receiver, because of that, they automatically reconnect to the receiver after a stateful switchover and same happens when the session is interrupted, the router is the one that re-establishes a new session.
Publication Types
There are two types of subscriptions: periodic and on-change.
With periodic subscription, data is streamed out to the destination at the configured interval. It continuously sends data for the lifetime of that subscription.
With on-change, data is published only when a change in the data occurs such as when an interface or OSPF neighbor goes down.
Software Stack
Multiple software stacks can be used to enable receiving, storing and visualizing this telemetry data, but the most popular at the moment that I found are TIG and ELK.
Using these tools in conjunction, we can build a reliable Streaming Telemetry Infrastructure.
TIG refers to Telegraf (Collection), InfluxDB (Storage) and Grafana (GUI visualization).
ELK refers to Elasticsearch (search and analytics engine), Logstash (Data processing pipeline) and Kibana (GUI visualization).
Additionally to these, we could use Prometheus or Splunk as another downstream consumers of the telemetry data, also Apache Kafka or RabbitMQ messaging bus could improve the Stream Telemetry Infrastructure.
This can give you an idea of how all the components relate.
Network Management Protocols
NETCONF
Network Configuration Protocol (NETCONF) is a network management protocol developed and standardized by the IETF Netconf working group, which provides a mechanisms to install, manipulate, and delete the configuration of network devices.
It uses an Extensible Markup Language (XML)-based data encoding for the configuration data as well as the protocol messages, the contents of both the request and the response are fully described in XML DTDs or XML schemas.
NETCONF can be used in concert with XML-based transformation technologies, such as XSLT, to extract the needed information from an XML file without modifying it and provide a system for automated generation of full and partial configurations.
The protocol operations are realized as remote procedure calls (RPCs) and the most common transport protocol for NETCONF is SSH with default TCP port assigned by IANA is 830. Other protocols can be used as transport protocols, but the second most common is TLS with TCP port number 6513 also assigned by IANA. A NETCONF server implementation must listen for connections to the ‘netconf’ subsystem on this port.
The session initiation flow for clients would be:
A client must open an SSH2 connection.
The server should sent its hello message, and the client should do the same. In this hello messages they express their list of netconf capabilities.
Next, the server should be waiting for <rpc> requests to process and the server should sent an <rpc-reply> for each <rpc> request. The client can add as many XML attributes to the <rpc> element as desired, and the server will return all those attributes in the <rpc-reply> element.
NETCONF defines the existence of one or more configuration datastores and allows configuration operations on them. They are defined as the complete set of configuration data that is required to get a device from its initial default state into a desired operational state. Some of these are familiar to those who have worked with Cisco equipment.
The running configuration datastore holds the complete configuration currently active on the network device. Only one of this type exists on the device, and it is always present. NETCONF protocol operations refer to this datastore using the <running> element.
Additional configuration datastores like startup or candidate, MAY be defined by capabilities. Such configuration datastores are available only on devices that advertise the capabilities.
Common NETCONF operations:
get-config: Retrieve all or part of a specified configuration datastore.
edit-config: Loads all or part of a specified configuration to the specified target configuration datastore. If the target configuration datastore does not exist, it will be created.
copy-config: Create or replace an entire configuration datastore with the contents of another complete configuration datastore. If the target datastore exists, it is overwritten, otherwise, a new one is created, if allowed.
delete-config: Delete a configuration datastore. The running configuration cannot be deleted.
RESTCONF
Representational State Transfer Configuration Protocol (RESTCONF) is another network management protocol based on HTTP and REST Principles, for configuring data defined in YANG data models, this provides a REST-like API for network devices.
RESTCONF uses HTTP methods (POST, GET, PUT, PATCH, and DELETE) to provide CRUD operations (Create, Read, Update, Delete), payload data is encoded with either XML or JSON and it provides a subset of NETCONF functionality implemented on top of HTTP/HTTPS.
gNMI and gNOI
gRPC Network Management Interface and gRPC Network Operation Interface, are protocols developed by Google and then contributed to the open source community.
These protocols are generic APIs as an alternative to NETCONF/RESTCONF to provide mechanisms to interact with network devices. The content provided through them can be modeled using YANG.
gNMI is used to install, manipulate, and delete the configuration of network devices, and also to view operational data.
gNOI is used to reboot, clear LLDP interfaces, clear BGP neighbor and other operational commands on network devices.
You can find the gNMI specifications, as well as gNOI gRPC-based micro services openly available at OpenConfig’s GitHub account.
These protocols use protobuf serialization format (explained in a previous post) and gRPC (HTTP/2.0) transport. gNMI can also use JSON IETF Encoding for YANG Data Trees and their subtrees, both the client and target must support JSON encoding.
We could see an example of this JSON encoding in Cisco’s configuration guide table 2, using the gRPC Get call and the openconfig-interfaces YANG model to get the status of the interface Loopback111.
gRPC is an open source remote procedure call protocol developed by Google for low-latency, scalable distributions for client/server communications. It provides a unique client library, automatically generated for your service in a variety of languages and platforms.
gRPC lets you define four kinds of service method:
Unary RPCs where the client sends a single request to the server and gets a single response back, just like a normal function call.
Server streaming RPCs where the client sends a request to the server and gets a stream to read a sequence of messages back.
Client streaming RPCs where the client writes a sequence of messages and sends them to the server, again using a provided stream. Once the client has finished writing the messages, it waits for the server to read them and return its response.
Bidirectional streaming RPCs where both sides send a sequence of messages using a read-write stream. Because of this support for bidirectional streaming, it can natively support streaming telemetry.
gRPC like many topics in these posts, is complex and we could go further into the details, but the idea for now is to understand the big picture so we can begin using the different components
The different calls that you can make though gRPC would be defined by the protobuf schema file and those service methods, in this case for the gNMI service or gNOI micro services.
Taking the gNMI.proto schema as an example, we can see the following: (The file is truncated to focus on the RPC services)
In this gnmi.proto file we can also understand the different requirements for each rpc call, for example when subscribing, the client needs to specify:
Path in the config tree.
Subscription type (target defined, on change, sample).
Subscription mode (once, stream, poll).
NETCONF vs RESTCONF vs gNMI
After understanding the surface of these different protocols, the most common question that comes to my mind is, which protocol would be the best?
Coming from a networking background, I would have to say that I haven’t had the experience yet to create a solid comparison like a software developer could, and this topic could be both subjective and personal, but I would have to say that it seems that gNMI is the way that everyone is evolving because of its runtime performance and “ease of use” thanks to Google’s integration with several programing languages. Personally, at the beginning I found it difficult to understand all these new concepts and relations.
Is worth noting that there is a lot of development done with NETCONF and because of that, it’s more feature-rich than the rest, it has more documentation and support from networking vendors. XML encoding could be challenging for some people, but I find it easier to begin with than protobuf or JSON for gNMI.
Finally, RESTCONF would be a great option if we need simplicity, it’s also stateless and a good protocol to be used for communication with orchestration tools (device-to-device communication) but not for multiple devices at the same time.
Like with everything in life, all of these protocols have their strengths and weaknesses and there is no one that fits all.
Automation Tools (Configuration Management)
There are many automation tools out there but I’ll narrow this down to the most used for configuration management (CM). This doesn’t mean that these tools are only useful for CM, but we are just going to get a broad overview of each within that scope, so we can get an idea of our use case.
Configuration management is a process for establishing and maintaining consistency, in our case, of the infrastructure’s performance, functional, and physical attributes with its requirements, design, and operational information throughout its life.
Some of these tools could use the network management protocols explained before to interact with the network devices, but depending on their architecture they mainly use SSH or SSL.
Ansible
Ansible is an open-source IT automation tool that can configure systems, deploy software, and orchestrate more advanced IT tasks. It manages machines in an agent-less manner using OpenSSH for transport (with other transports and pull modes as alternatives), and its own language to describe system configuration. The language for Ansible can be a hybrid, where it mainly works as procedural but some modules can perform declarative-style configuration.
Just as a reminder, as you might expect, a declarative language is where you say what you want without having to say how to do it (e.g. I want to have 5 EC2 instances deployed in AWS). While in procedural programming, you have to specify exact steps to get the result, following the same example as before, you would need to know how many EC2 instances are already deployed in advance, for you to deploy or shutdown “x” amount of instances, so you end with 5 in total, specifying the steps for each action.
Ansible is decentralized and relies on existing OS credentials to control access to remote machines. If needed, Ansible can easily connect with Kerberos, LDAP, and other centralized authentication management systems.
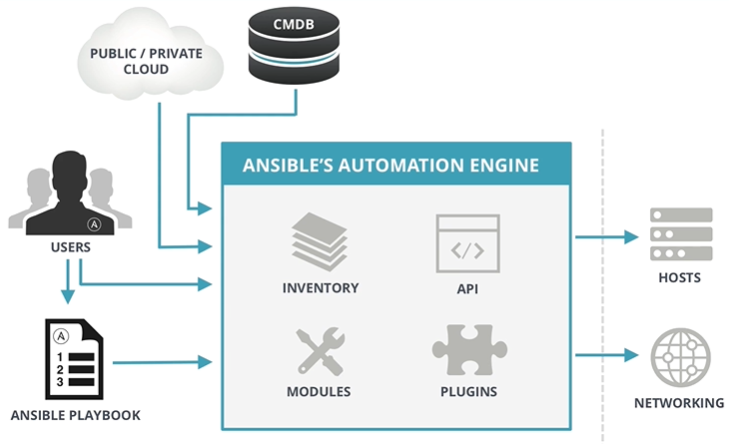
Taking a quick look at Ansible’s documentation we could have a good initial idea of how it works.
Ansible Architecture.
First you would need a Control node which is any machine with Ansible installed. You can use any computer that has Python installed on it as a control node - laptops, shared desktops, and servers can all run Ansible. However, you cannot use a Windows machine as a control node. You can have multiple control nodes.
You would need an Inventory, which is a list of managed nodes. An inventory file is also called a hostfile. Your inventory can specify information like IP address for each managed node. An inventory can also organize managed nodes, creating and nesting groups for easier scaling.
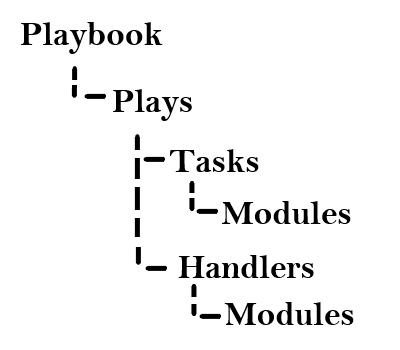
And the key component for Ansible, Playbooks, they are ordered lists of tasks, saved so you can run those tasks in that order repeatedly. Playbooks can include variables as well as tasks and there are many ways to source variables.
The high level structure of a playbook could be visualized as follows:
Playbook Structure.
Modules are the units of code Ansible executes. Each module has a particular use, you can invoke a single module with a task, or invoke several different modules in a playbook.
You can execute a tasks by running a single task once with an ad-hoc command, run Ansible with an ansible-playbook or use Ansible Tower (Red Hat's enterprise solution).
Playbooks are written in YAML and are easy to read, write, share and understand. For example, this playbook with multiple plays from the Ansible docs:
----hosts:webserversvars:http_port:80max_clients:200remote_user:roottasks:-name:ensure apache is at the latest versionyum:name:httpdstate:latest-name:write the apache config filetemplate:src:/srv/httpd.j2dest:/etc/httpd.confnotify:-restart apache-name:ensure apache is runningservice:name:httpdstate:startedhandlers:-name:restart apacheservice:name:httpdstate:restarted-hosts:databasesremote_user:roottasks:-name:ensure postgresql is at the latest versionyum:name:postgresqlstate:latest-name:ensure that postgresql is startedservice:name:postgresqlstate:started
Many Ansible deployments also use AWX, an open source web-based GUI, REST API, and task engine built on top of Ansible. AWX is used by Ansible Tower but later one (commercial) would take selected releases of AWX and harden them for long-term supportability. Another characteristic of AWX is that direct in-place upgrades between AWX versions are not supported, requiring the use of a backup and restore tool to perform upgrades.
Ansible Tower is a product and support offering from Red Hat, based on both Ansible and AWX open source projects, which helps teams manage complex multi-tier deployments by adding control, knowledge, and delegation to Ansible-powered environments.
It provides a GUI dashboard, role-based access control, job scheduling, multi-playbook workflow, REST API and more, expanding Ansible’s power to an enterprise-level environment.
Puppet
The name “Puppet” can bring to some confusion at first since it is the name of a company and the products they created, the one that we are going to discuss is the Open Source Puppet project which we will be referring as Puppet, but is worth mentioning that like Red Hat, Puppet has also the commercial “Puppet Enterprise” offering, built for teams at enterprise scale and support needs.
Like Ansible, Puppet is an open-source IT automation tool that can help us configure systems, it also uses its own Puppet’s Domain-Specific Language (DSL) or Puppet Code where you define the desired state of the systems. This means that Puppet code is declarative which differs from Ansible.
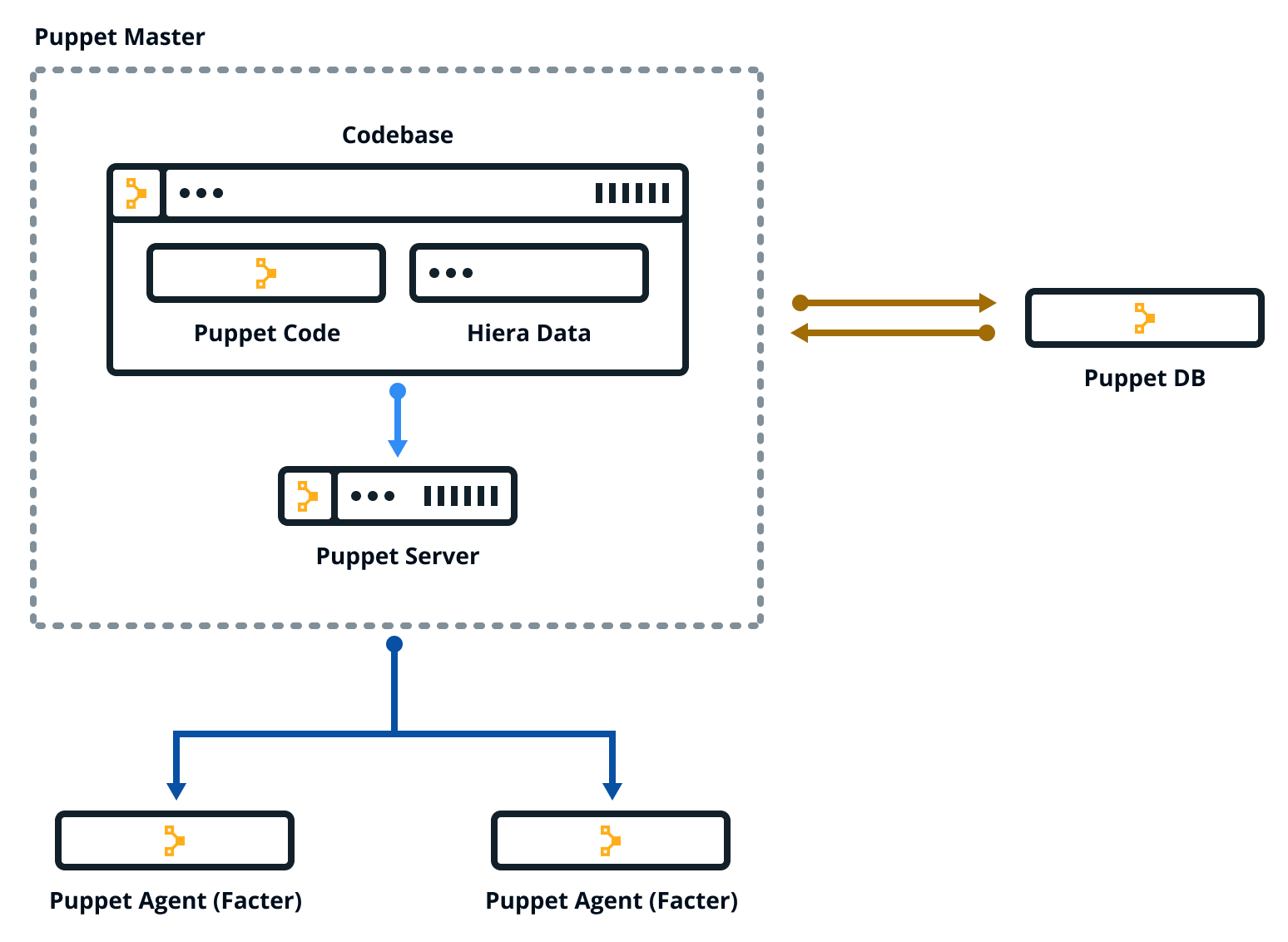
Puppet automates the process of getting these systems into that state and keeping them there by using a client/server or master/agent architecture. The Puppet agent translates your code into commands and then executes it on the systems you specify, in what is called a Puppet run, this implies that there is the need for interoperability between the agent and the system that you wish to configure, in our case, there are several networking modules for Cisco, Arista, etc.
Puppet platform components are Puppet Server, Puppet agent, Facter, Hiera, and PuppetDB.
Puppet Platform Overview.
Masters and agents communicate over HTTPS using SSL certificates and Puppet includes a built-in certificate authority for managing certificates. The Puppet Server performs the role of the master node and also runs an agent to configure itself.
Facter is Puppet’s inventory tool that gathers facts about an agent node such as its hostname, IP address, etc. The agent sends these facts to the master in the form of a special Puppet code file called a “manifest”.
This is the information the master uses to compile a “catalog”, a JSON document describing the desired state of a specific agent node. Each agent requests and receives its own individual catalog, enforces that desired state on the node it’s running on and sends a report back to the master.
Hiera is a tool that allows you to separate the data from the code and place it in a centralized location, this allows you to secure and define known parameters and variations.
All of the data generated by Puppet (for example facts, catalogs, reports) is stored in the Puppet database (PuppetDB). PuppetDB provides an API for other applications to access Puppet’s collected data with PuppetDB queries.
Is worth mentioning that the creators of Puppet around 2018 created Bolt, which is another open source orchestration tool that help us automate our infrastructure. The main difference with Puppet is that is agentless, just like Ansible. I’m not going to dive into it since I think is not worth the time right now, Ansible is more mature and widely used, but if the adoption of this tool grows, I might do another post for it.
Chef
Just like Puppet, Chef is an automation company which has developed several open-source products (Chef Infra Client, Chef InSpec and Chef Habitat) that it leverages to provide a full suite of enterprise capabilities (Chef Automate) for node visibility and compliance.
Chef Automate Architecture.
Chef uses a pure-Ruby, domain-specific language (DSL) for writing system configuration “recipes”. It is more common to be used in client/server mode, but it can also work in a standalone mode named “chef-solo”, which is a way of running the Chef Infra Client against the chef-repo on a local machine as if it were running against the Chef Infra Server.
All communication with the Chef Infra Server must be authenticated using the Chef Infra Server API, which is a REST API that allows requests to be made to the Chef Infra Server. Chef Infra Client runs are set to a default 30-minute interval with a 5-minute splay and like Ansible its code is procedural
Chef is comprised of the following elements:
Chef Infra Components.
Please take into account that this is a high level summary of Chef Infra, and I must say that there is a lot of information regarding the functionalities and specificities of each of these components in their documentation page, which I think is a must read to everyone who would like to work with this tool.
Personally, I found it complex or more difficult to wrap my head around it in comparison with Ansible and Puppet, this could be an important factor for its adoption in the networking world, which I haven’t encountered that much.
The Chef Workstation package includes Chef Infra Client and other tools like InSpec, Test Kitchen and other tools necessary for developing and testing your infrastructure with Chef products. In workstations you can author cookbooks, interact with the Chef Infra Server, and interact with nodes.
The chef-repo is the repository structure in which cookbooks are authored, tested, and maintained.
The chef-repo should be synchronized with a version control system (such as git), and then managed as if it were source code. The directory structure within the chef-repo varies. Some organizations prefer to keep all of their cookbooks in a single chef-repo, while other organizations prefer to use a chef-repo for every cookbook.
Cookbooks contain recipes, attributes, custom resources, libraries, files, templates, tests, and metadata. They are uploaded to the Chef Infra Server from these workstations and some cookbooks are custom to the organization while others are based on community cookbooks available from the Chef Supermarket.
A recipe is the most fundamental configuration element within the organization. Is mostly a collection of resources, defined using patterns (resource names, attribute-value pairs, and actions) and it MUST define everything that is required to configure part of a system. It also, MUST be stored in a cookbook and added to a run-list before it can be used by the Client.
Is worth noting the most important command-line tools included in the workstation package, which are, Chef Infra to work with items in a chef-repo, and Knife to interact with nodes or work with objects on the Chef Infra Server.
Chef Infra Server acts as a hub for configuration data, it stores cookbooks, policies applied to nodes and metadata that describes registered nodes that are managed by Infra Client. Infra Servers have several components like load balancing for the API, Data Stores, Message Queues, etc.
Nodes use Infra Client to ask the Infra Server for configuration details, such as recipes. Infra Client then does as much of the configuration work as possible on the nodes themselves.
Chef Infra Client is an agent that runs locally on every node that is under management by Chef Infra Server. When Chef Infra Client runs, performs all of the steps required for bringing a node into the expected state, for a more detailed overview of the steps perform during a Client run you could refer to Chef's documentation
Ohai is a tool like "Facters" for Puppet, which is used to collect system configuration data in the managed node, which is provided to Chef Infra Client for use within cookbooks. Ohai is run by Chef Infra Client at the beginning of every Chef run to determine system state.
Cisco NSO
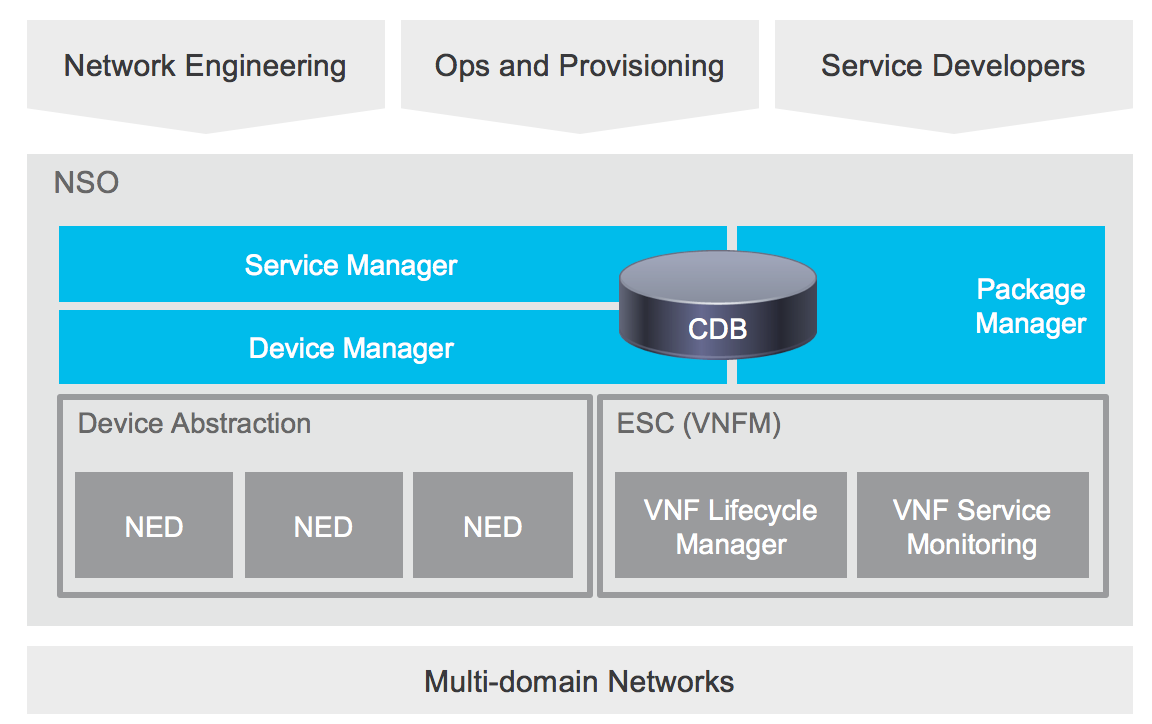
Cisco’s Network Services Orchestrator or NSO, is also an orchestrator for IT automation, but in comparison with the ones explained before, it goes further and help us reach a higher level perspective for lifecycle services automation, this means that NSO is meant to have knowledge of the services and their relation to the lower layers in the infrastructure that enable that service. NSO could be called a controller for controllers.
In today’s networks there are multiple domains, like NFV (Virtualized), SDN (Software-Defined Networking) and legacy physical networks, so for NSO to achieve this service orchestration, it spans across all those domains, communicating the controllers for those domains or directly to the physical devices, abstracting the details of the configuration. NSO is a model driven (YANG) platform and it supports multi-vendor networks through a variety of Network Element Drivers developed by their Tail-f team. (NEDs)
NSO Components.
CDB (Configuration Database) is a tree-structured database that is controlled by a YANG schema, so all the information stored is validated against the schema. The CDB always contains NSO's view of the network configuration, there could also be changes done to the devices directly, but NSO can check and handle those out of sync devices, by re-deploy reconcile (write NSOs view to the device) or oob-reconcile (change service intent in NSO to accept those changes)
Transactions towards CDB exhibits ACID properties, the transaction have to be successful across participating devices and in the CDB master copy, or the whole transaction is aborted and changes are automatically rolled-back.
NFV Orchestration is the NSO component that integrates with the VNF Manager (VNFM), in this case for the figure, the Cisco Elastic Services Controller, to onboard VNFs. It would assume the NFC-O role in the NFV MANO framework
Service Manager, every business have their own context and different needs and we usually translate those needs onto device configurations, integrations, policies, etc., but usually these services are not consistently implemented, we lose track of the inter-dependency between services and configurations, and other inherent complexities of service management. What NSO allows us to do is to develop a service, expressing the mapping from a YANG service model to the corresponding device YANG model, in a declarative mapping where no sequencing is defined. This allows us to disengage from the vendor-specific CLI commands.
Since NSO's main benefit is that allows us to manage services life cycles, the service definition would be crucial task, which I found a complex topic that needs to be addressed on its own, but as a quick overview, every service model or package is comprised of:
YANG service data model, which defines the architecture, API, CLI or high level constraints for the service, just like an OpenConfig YANG data model defines what can be changed or accessed in a switch.
Logic component (Optional) which as the name implies, it adds some programming logic that cannot be achieved simply by the service model or templates. This can be Python or Java code.
Templates which maps the service intent to a device model with XML files, similar to what NETCONF uses to define the attributes it would like to configure. Templates can also have processing instructions, like setting variables, conditional expressions, for loops, etc.
Package-meta-data.xml, like requirements.txt, it defines versions, package dependencies and components provided.
Testing (Optional) in case you would like to do some unit testing or retrieve any operational data from the devices to confirm that the service has been deployed successfully.
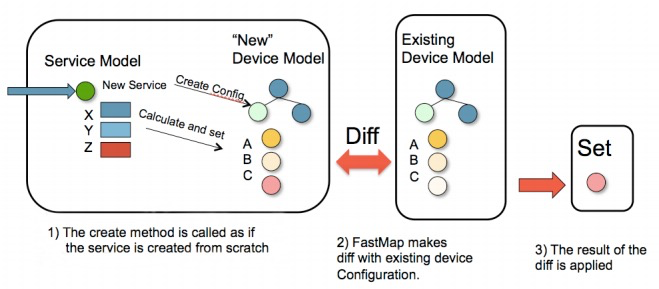
To find the minimum change that needs to be applied for any possible change in the service, the service algorithm FASTMAP was developed, which covers the service life cycle (creation, changing and deletion).
It does this by generating the changes needed from an initial create for the service, after which the reverse device configuration (undo) is stored together with the service instance. When a change to the service instance occur, NSO undoes the previous results of the service creation code, then it runs the logic to create the updated service, and finally executes a diff between the new configuration and the current one. This diff is then sent to the devices.
FASTMAP visualization.
There are different ways to implement services:
Manual, which is basically manually loading different XML templates to go through the actions that comprise the service, but this is not really useful for production, since it doesn't automate the service lifecycle.
FastMap services, are basic service models where they do not have dependencies between stages, like a simple service for Vlan configuration in a specific environment.
RFM (Reactive FastMap) services, are the evolution from simple FastMap services and like the name states, allows us to bring reactive actions or conditional stages to the services to tackle more complex scenarios, like VM deployments for example, where we have to wait for an allocation of resources to be done to later deploy an specified VM into those resources.
RFM depends heavily on re-deploys by following the different stages defined in the service models, each time it re-deploys, it checks if the stage is already reached, by like we explained before, the FastMap would result in a no-op, since the configs would be the same (no diff). It would continue to re-deploy the service by applying the changes needed, until it reaches the ready state.
Nano Services are the newest addition that addresses the shortcomings of RFM services, which the most important one is the deletion or updates in stages of the service, since the RFM service works as a block, deletion would be as a whole for the service. There are some workarounds (Facade Services) in RFM but it's not ideal.
With Nano Services, we can see every stage in the plan as a self-contained components that can be deleted or updated in a staged manner.
I found these videos really useful in case you would like to go deeper into this topic, which I can say is really extensive.
NED or Network element drivers, comprise the network-facing part of NSO, since they would be some form of "device adaptor" which communicates over the native protocol supported by the device, such as NETCONF, REST, XML, CLI, and SNMP, whenever a configuration change needs to be applied.
NEDs offer support for multivendor devices, since they need to be installed for every type of device OS used.
They make use of YANG data models for rendering or doing this "translation", so if the device offers a NETCONF/YANG interface then no development is required, as the NED can be generated automatically from the device model.
NEDs for legacy protocols are sold at a price and usually maintained by Cisco or even other vendors. NETCONF/YANG NEDs are generally free and there is also the option to develop your own NEDs.
Cisco's IOx Application Hosting Infrastructure
With the new Cisco platforms becoming more flexible and less monolithic (x86 processors), application hosting became an option to give administrators a platform for leveraging their own tools and utilities.
There are several ways to host an application on Cisco platforms:
UCS Express, based in multipurpose x86 blade servers modules that provide compute services to Cisco platforms mainly for branch offices where there is significant resource needs as bare-metal or hypervisor.
IOx, also known as Cisco IOx (IOS + LinuX), is the Cisco application framework (CAF) that provides application hosting capabilities to these platforms without the need for extra modules, this framework provide a fundamental structure to support the development of applications.
IOx supports:
KVM-based virtual machines, intended for small VMs with limited resource needs, it allows you to deploy industry-standard KVM virtual machine directly in many routing platforms.
LXC Linux containers, to deploy application code and its dependencies with a smaller footprint than VMs. Native Docker containers are not yet supported in IOx, but there is a Docker Toolchain to develop applications for IOx.
The IOx application created using a Docker image is run using LXC and AUFS on a compatible IOx platform.
Guestshell, is a pre-built and installed container with 64-bit Linux environment based on CentOS 7, running on IOS XE and NX-OS platforms built on top of IOx. Guestshell is intended for:
Agent or script hosting, like using Python or integrating with events by Cisco Embedded Event Manager (EEM)
Utility Hosting, like RPM packet manager or other Linux utilities.
Guest Shell runs on an LXC container and it is isolated from the host kernel, running as an unprivileged container.
Access to the Guest Shell via SSH is restricted to the user with the highest privilege (15) in Cisco IOS, this user is a sudoer, and can perform all root operations. Commands executed through the Guest Shell are executed with the same privilege that a user has when logged into the Cisco IOS terminal.
Within the Guest Shell we can access Cisco's CLI by using the "dohost" command built into Guest Shell, this is limited to exec privilege commands, so there is no access to config mode with this command.
The Guest Shell network access can be achieved using three different options:
Management port (default), since Guest Shell allows applications to access the management network, this is leveraged by Day Zero provisioning like ZTP, allowing the switch to receive options from a DHCP server, downloading a configuration script and running it within a guestshell, to finally configure the device.
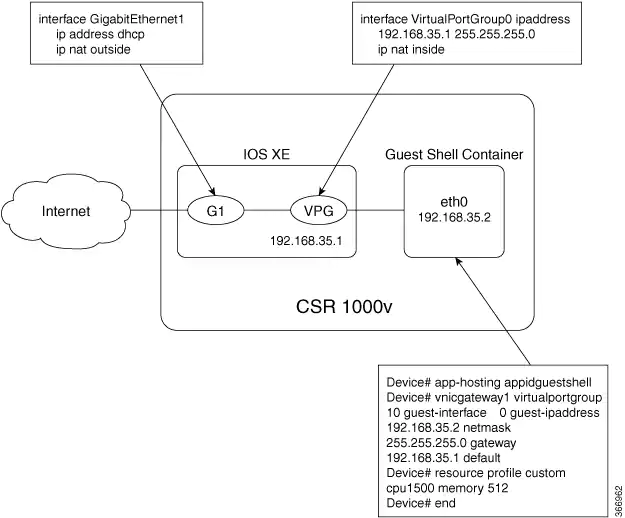
VirtualPortGroup (VPG), for platforms without a management port and routing capable, a VirtualPortGroup can be associated with Guest Shell in the Cisco IOS configuration.
AppGigabitEthernet port, for switching platforms like Catalyst 9k series, the support for AppGigabitEthernet interface is provided to allow tagging the traffic to specific vlans. All other Catalyst switches use the management port.
For the VPG option is necessary to configure a NAT policy, which is why is applicable only to Cisco routing platforms. Below you can see an example from Cisco's documentationGuest Shell VirtualPortGroup.
For high availability switchover scenarios (stacks), the Guest Shell state is maintained during a switchover, this is because when Guest Shell is initially installed, a gs_script directory is automatically created in the flash filesystem and is synchronized across stack members. During a switchover, only contents of the gs_script directory are synchronized across all stack members.
Capabilities and features of IOx may vary depending on the platform, so Cisco provides this platform support matrix.